

Negli ultimi anni, i Large Language Models (LLM) hanno trasformato il modo in cui interagiamo con le informazioni. Tuttavia, i modelli faticano ancora con le cosiddette "allucinazioni" e non possiedono una conoscenza aggiornata o privata dei dati aziendali. Per risolvere questo problema, la tecnica dello standard RAG (Retrieval-Augmented Generation) è diventata la norma.
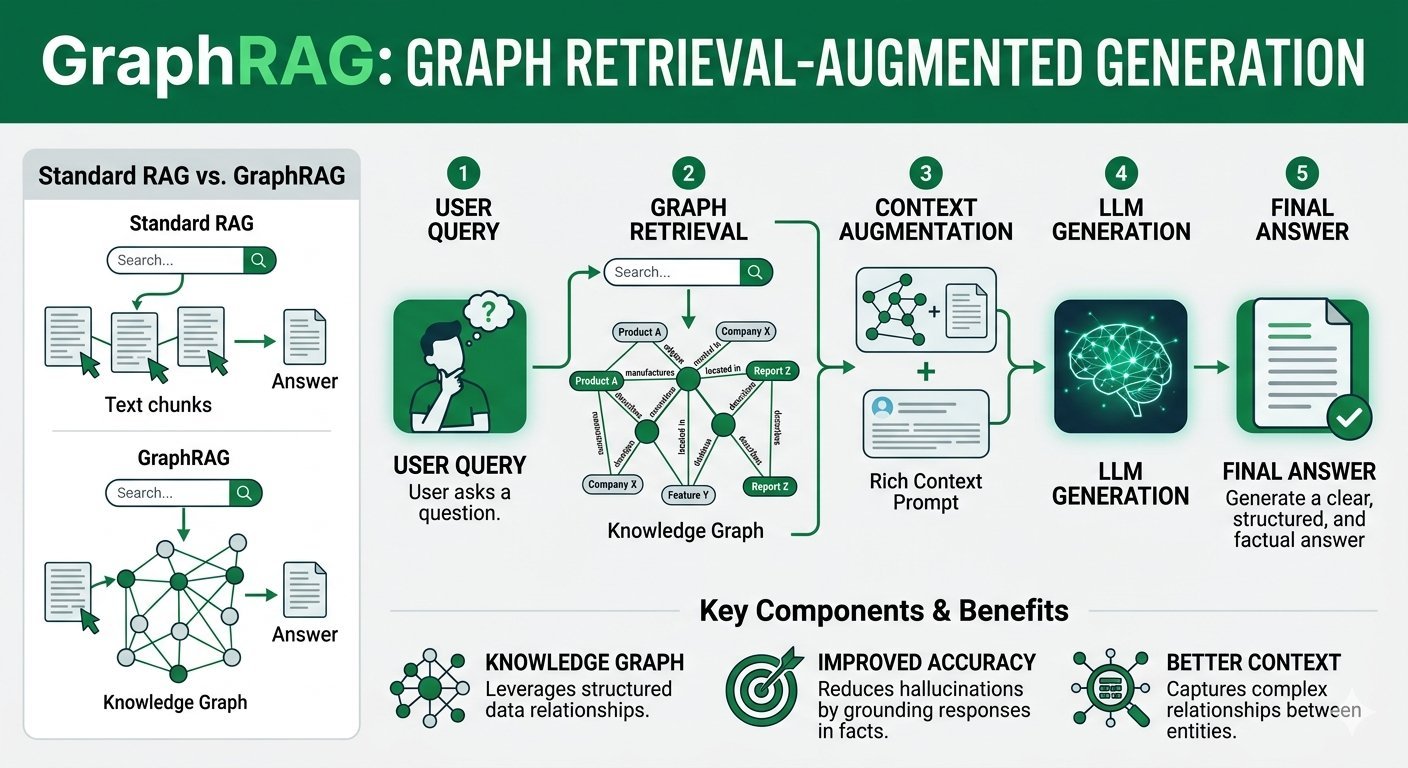
Ma il RAG tradizionale ha un limite strutturale: tratta i documenti come frammenti isolati di testo. È qui che entra in gioco GraphRAG (Knowledge Graph-based RAG), un approccio evoluto che unisce la potenza dei LLM alla precisione strutturata dei Grafi della Conoscenza (Knowledge Graphs).
1. Cos'è GraphRAG?
Mentre il RAG tradizionale si basa sulla ricerca vettoriale per trovare frammenti di testo simili a una query, GraphRAG estrae e collega entità (persone, luoghi, concetti, oggetti) e le loro relazioni all'interno di una rete (un grafo).
Definizione: GraphRAG è un'architettura di intelligenza artificiale che potenzia la generazione di risposte dei LLM non solo recuperando testi pertinenti, ma navigando all'interno di una mappa mentale strutturata (Grafo della Conoscenza) creata a partire dai dati stessi.
Ideato e reso celebre dai team di ricerca di Microsoft, GraphRAG permette al modello di comprendere il contesto globale e le connessioni nascoste tra informazioni apparentemente slegate.
2. Il Limite del RAG Tradizionale (Baseline RAG)
Per capire l'importanza di GraphRAG, dobbiamo guardare dove fallisce il RAG classico (basato solo su Vector Search):
- Mancanza di visione globale: Se chiedi "Quali sono i principali temi emersi nei report finanziari degli ultimi 5 anni?", il RAG tradizionale cerca frammenti di testo specifici. Non è in grado di sintetizzare informazioni distribuite su migliaia di pagine.
- Perdita di relazioni: Se il Documento A dice "Marco lavora per l'Azienda X" e il Documento B dice "L'Azienda X ha acquisito l'Azienda Y", il RAG classico potrebbe non capire che Marco è indirettamente collegato all'Azienda Y, a meno che i due testi non siano memorizzati vicini.
- Frammentazione: La segmentazione del testo (chunking) spezza i concetti, isolando informazioni che dovrebbero essere unite.
3. Come Funziona GraphRAG: L'Architettura
Il processo di GraphRAG si divide in due macro-fasi: Indicizzazione (Indexing) e Recupero/Generazione (Querying).
Fase 1: L'Indicizzazione (Creazione del Grafo)
- Source Text Chunking: I documenti vengono divisi in parti di testo.
- Element Extraction: Un LLM analizza ogni frammento per identificare tutte le entità (es. Persona: Elon Musk, Azienda: Tesla) e le loro relazioni (es. Elon Musk ➔ CEO di ➔ Tesla).
- Graph Generation: Queste entità e relazioni diventano nodi e archi di un grafo.
- Community Detection: Algoritmi di rete (come l'algoritmo di Leiden) raggruppano i nodi strettamente correlati in "comunità" (es. una comunità per il settore "Automotive", una per "SpaceX").
- Community Summarization: Il LLM genera un riassunto per ogni singola comunità. Questo è il segreto per rispondere a domande globali.
Fase 2: Il Recupero e la Generazione (Querying)
Quando l'utente fa una domanda, GraphRAG può operare in due modalità:
- Global Search: Utilizza i riassunti delle comunità per rispondere a domande olistiche (es. "Quali sono i trend di mercato?").
- Local Search: Naviga tra i nodi specifici del grafo per rispondere a domande dettagliate (es. "Chi ha approvato il budget del progetto X?").
4. Confronto Diretto: Baseline RAG vs. GraphRAG
| Caratteristica | Baseline RAG (Vettoriale) | GraphRAG (Grafo + Vettoriale) |
| Struttura Dati | Frammenti di testo (Chunks) non connessi | Nodi, relazioni e comunità strutturate |
| Tipo di Domande | Specifiche e puntuali ("Qual è il prezzo di X?") | Globali e riassuntive ("Quali sono i rischi emersi?") |
| Comprensione del Contesto | Limitata al frammento di testo trovato | Ampia, basata sulle connessioni di rete |
| Costi di Indicizzazione | Molto bassi (solo embedding vettoriali) | Alti (richiede molte chiamate LLM per estrarre il grafo) |
| Allucinazioni | Moderate (ridotte rispetto al LLM puro) | Minime (ancorate alla struttura logica del grafo) |
5. I Vantaggi Chiave di GraphRAG
- Ragionamento Multi-Hop: Capacità di collegare i puntini. Se per rispondere servono tre informazioni separate contenute in tre faldoni diversi, GraphRAG segue gli archi del grafo e unisce i punti in modo logico.
- Sintesi di alto livello: È imbattibile nel fare riassunti di interi dataset (migliaia di PDF, email o trascrizioni).
- Tracciabilità e Spiegabilità: È possibile tracciare esattamente il percorso logico compiuto sul grafo per generare la risposta, rendendo l'IA meno "scatola nera".
6. Casi d'Uso Aziendali e Applicazioni Reali
A. Intelligence e Investigazioni
Analisi di file giudiziari o report di intelligence. GraphRAG può mappare reti criminali, transazioni finanziarie sospette e legami societari nascosti in milioni di pagine di documenti.
B. Ricerca Scientifica e Farmaceutica
Analisi della letteratura medica. Un ricercatore può chiedere: "Ci sono correlazioni indirette tra la molecola X e gli effetti collaterali del farmaco Y?". Il sistema naviga le relazioni tra geni, malattie e composti chimici.
C. Customer Support ed Enterprise Search
Nelle grandi aziende, le informazioni sono frammentate tra Sharepoint, Slack, e-mail e Jira. GraphRAG unifica la conoscenza aziendale, permettendo ai dipendenti di fare domande complesse sui processi interni.
7. Sfide e Svantaggi di GraphRAG
Nonostante sia una tecnologia rivoluzionaria, GraphRAG presenta alcune sfide ingegneristiche ed economiche:
- Costi di computazione elevati: Costruire il grafo richiede che un LLM legga tutto il testo per estrarre entità e relazioni. Per dataset immensi, questo si traduce in milioni di token e costi API significativi in fase di setup.
- Complessità di implementazione: Gestire un database a grafi (come Neo4j) unito a un vector database richiede competenze infrastrutturali avanzate rispetto a un semplice RAG vettoriale.
- Latenza: La navigazione del grafo e la sintesi delle comunità possono richiedere più tempo rispetto a una semplice ricerca vettoriale, sebbene l'ottimizzazione stia riducendo questo gap.
Conclusioni
Il RAG tradizionale ha aperto le porte dell'IA aziendale, ma GraphRAG rappresenta la maturità di questa tecnologia. Trasformando dati non strutturati in una rete di conoscenza interconnessa, permette alle aziende non solo di "cercare" informazioni, ma di comprendere veramente la totalità del proprio patrimonio informativo.
Mentre i costi dei modelli LLM continuano a scendere, l'adozione di GraphRAG è destinata a diventare lo standard de facto per qualsiasi applicazione di IA generativa che richieda precisione, sintesi globale e ragionamento complesso.
Commenti (0)
Nessun commento ancora.


